簡稱 CNN,一種人工神經網路,處理資料具有 格狀結構(grid-like structure) 應用
CNN特點是使用 卷積運算(convolution operation) 代替一般神經網路 全連接運算(fully-connected operation)
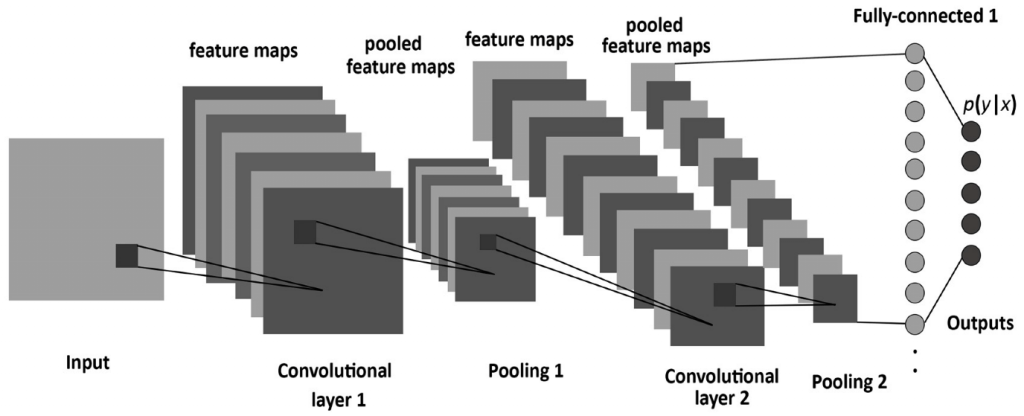
圖片來源:初探卷積神經網路
卷積層 (Convolutional Layer)
卷積核 (Kernel):小型矩陣,在輸入圖像上滑動,計算每個位置的輸出特徵圖(Feature Map):卷積核在輸入圖像上滑動後得到的輸出,代表提取到的特徵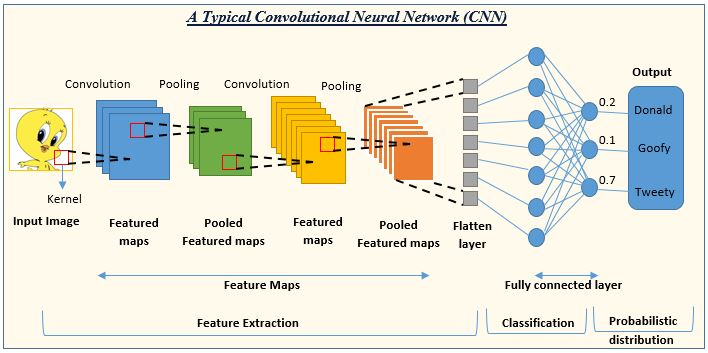
池化層(Pooling Layer)
下采樣(Downsampling):減少特徵圖大小,降低計算量,同時保留主要特徵常見池化方式: 最大池化 (Max Pooling)、平均池化 (Average Pooling)
全連接層(fully-connected layer):負責對池化層輸出的特徵進行分類或迴歸
局部連接: 卷積核只與輸入圖像的局部區域連接,減少參數數量權重共享: 同一個卷積核在整個圖像上共享權重,提高模型泛化能力層次化特徵提取: 深層卷積層能夠提取到更抽象高層特徵影像識別(image recognition)
物件偵測(object detection)
影像分割(image segmentation)
自然語言處理(natural language processing)
語音識別(speech recognition)
卷積運算(convolution operation)
池化運算(pooling operation)
激勵函數(activation function)
損失函數(loss function)
優化演算法(optimization algorithm)
卷積運算是CNN核心運算,提取輸入資料局部特徵。卷積運算將輸入資料與卷積核進行逐元素相乘,然後對結果進行累加。卷積核大小決定卷積運算的感受野,也就是卷積運算輸出每個元素所依賴輸入資料範圍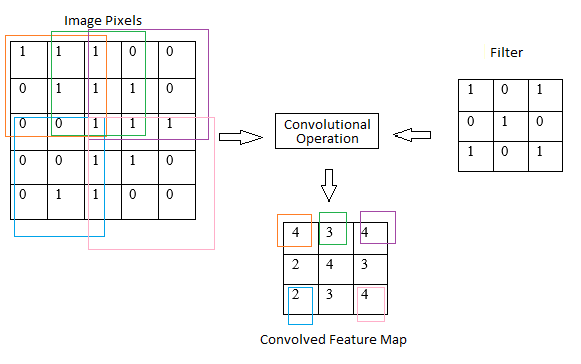
圖片來源:(https://www.researchgate.net/figure/Convolution-Operation-or-kernels-For-each-input-image-the-convolution-operation-is_fig2_350487754)
O = I * K
O |
卷積運算輸出 |
|---|---|
I |
輸入資料 |
K |
卷積核 |
輸入一個 3x3 矩陣,卷積核為一個 2x2 矩陣,則卷積運算輸出一個 2x2 矩陣
I = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
K = [[1, 2],
[3, 4]]
O = [[19, 22, 25],
[43, 50, 57]]
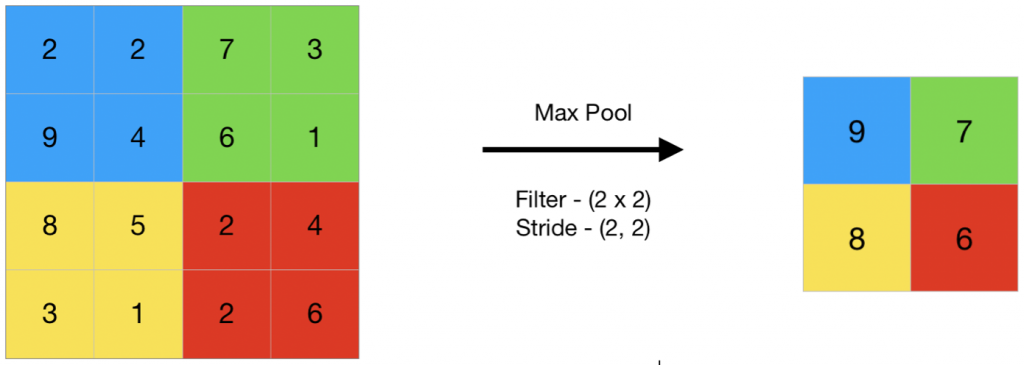
池化運算用在對卷積運算輸出的特徵進行降維和壓縮,以減少模型的參數量和計算量。通常採用 最大池化(max pooling) 或 平均池化(average pooling) 兩種方式
最大池化運算 會對輸入資料每個子區域取 最大值 作為輸出平均池化運算 會對輸入資料每個子區域取 平均值 作為輸出O = pool(I)
O |
池化運算輸出 |
|---|---|
I |
輸入資料 |
pool |
池化函數,例如:最大池化或平均池化 |
輸入一個 4x4 矩陣,採用最大池化運算,池化窗口大小為 2x2,則池化運算輸出一個 2x2 矩陣
I = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]]
O = [[5, 7],
[11, 13]]
激勵函數對神經元的輸出進行非線性變換,提高模型表達能力。常用激勵函數包括 Sigmoid函數、ReLU函數 和 Tanh函數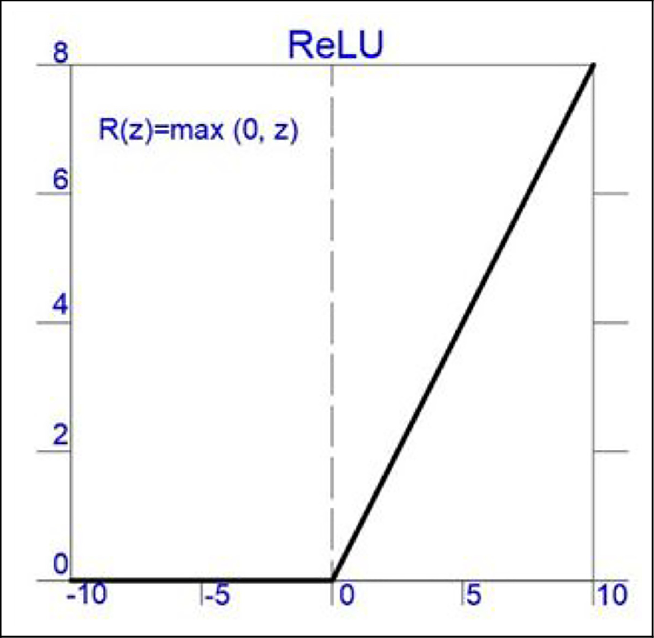
圖片來源:(https://www.researchgate.net/figure/Activation-function-ReLu-ReLu-Rectified-Linear-Activation_fig2_370465617)
f(x) = sigmoid(x) = 1 / (1 + exp(-x))
f(x) = relu(x) = max(0, x)
f(x) = tanh(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))
損失函數衡量模型預測值與真實值之間差距。常用損失函數包括 均方誤差(MSE) 和 交叉熵(cross-entropy)
L(y, y') = MSE(y, y') = (y - y')^2
L(y, y') = cross-entropy(y, y') = -y' * log(y) - (1 - y') * log(1 - y)
優化演算法更新模型參數,以降低損失函數的值。常用優化演算法包括 梯度下降(gradient descent) 和 Adam
theta = theta - alpha * grad(L(theta))
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D,
Flatten, Dense
# 假設資料已經準備好,X_train, y_train, X_test, y_test 分別為訓練集和測試集的影像資料和標籤
# 建立模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
MaxPooling2D((2, 2)),
Flatten(),
Dense(10, activation='softmax')
])
#
編譯模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 訓練模型
model.fit(X_train, y_train, epochs=5)
# 評估模型
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
資料來源:卷積神經網路
卷積神經網路(Convolutional neural network, CNN) — CNN運算流程
Day 06:處理影像的利器 -- 卷積神經網路(Convolutional Neural Network)

